Manipulación de datos en R con dplyr

Data frames
El data frame es una estructura de datos muy importante en R. La estructura de un data frame consiste en que cada fila representa un observación y que cada columna representa una variable, medida o característica de dicha observación.
Dada la importancia de los data frames, es importante poseer un conjunto de herramientas para trabajar con los mismos. En capítulos anteriores hemos discutido algunas herramientas como la función subset() y el uso de los operadores [ y $ para extraer subconjuntos de datos en data frames. Sin embargo, otras operaciones, como filtros, reordenar, etc. pueden ser a menudo una labor tediosa. El paquete dplyr esta diseñado para mitigar muchos de los problemas y proporcionarnos un conjunto de rutinas altamente optimizadas para el manejo de data frames.
El paquete dplyr
El paquete dplyr fue desarrollado por Hadley Wickham de RStudio y es un versión optimizada de su paquete plyr. El paquete dplyr no proporciona ninguna nueva funcionalidad a R per se, en el sentido que todo aquello que podemos hacer con dplyr lo podríamos hacer con la sintaxis básica de R.
Una importante contribución del paquete dplyr es que proporciona una "gramática" (particularmente verbos) para la manipulación y operaciones con data frames. Con esta gramática podemos comunicar mediante nuestro código que es lo que estamos haciendo en los data frames a otras personas (asumiendo que conozcan la gramática). Esto es muy útil, ya que proporciona una abstracción que anteriormente no existía. Por último, cabe destacar que las funciones del paquete dplyr son muy rápidas, puesto que están implementadas con el lenguaje C++.
La grámatica de dplyr
Algunas de los principales "verbos" del paquete dplyr son:
- select: devuelve un conjunto de columnas
- filter: devuelve un conjunto de filas según una o varias condiciones lógicas
- arrange: reordena filas de un data frame
- rename: renombra variables en una data frame
- mutate: añade nuevas variables/columnas o transforma variables existentes
- summarise/summarize: genera resúmenes estadísticos de diferentes variables en el data frame, posiblemente con strata
- __%>%_ : el operador "pipe" es usado para conectar múltiples acciones en una única "pipeline" (tubería)
Argumentos comúnes en las funciones dplyr
Todas las funciones que discutiremos en este capítulo tienen en común una serie de argumentos. En particular,
- El primer argumento es el data frame
- Los otros argumentos describen que hacer con el data frame especificado en el primer argumento, podemos referirnos a las columnas en el data frame directamente sin utilizar el operador $, es decir sólo con el nombre de la columna/variable.
- El valor de retorno es un nuevo data frame.
- Los data frames deben estar bien organizados/estructurados, es decir debe existir una observación por columna y, cada columna representar una variable, medida o característica de esa observación. Para ello, es muy útil es uso del paquete tidy. (lo veremos en capítulos posteriores).
Instalación del paquete dplyr
Podemos instalar el paquete desde CRAN o desde GitHub.
## Instalación desde CRAN
install.packages("dplyr")
## Instalación desde GitHub
library(devtools)
install_github("hadley/dplyr")
Después de la instalación es importante que lo carguemos en nuestra sesión R :
library(dplyr)Es posible que cuando carguemos el paquete nos aparezcan una serie de warnings, esto es debido que el paquete tiene funciones con el mismo nombre que en otros paquetes. Por el momento haremos caso omiso a estos avisos.
Recomiendamos consultar la documentación de las funciones:
?select
?filter
?arrange
?mutate
?summarise
?group_byselect()
Lo primero sera instalar el paquete con el conjunto de datos que utilizaremos para los ejemplos:
install.packages("devtools")
devtools::install_github("rstudio/EDAWR")Tendremos que cargar la libreria para poder utilizarla:
library(EDAWR)Podemos echar un vistazo al conjunto de datos mediante ? or el comando Viem():
?storms
?cases
?pollution
?tb
View(storms)
View(cases)
View(pollution)
View(tb)Con la función select podemos seleccionar columnas de un data frame:
Visualizamos el contenido del data frame storms:
storms## Source: local data frame [6 x 4]
##
## storm wind pressure date
## (chr) (int) (int) (date)
## 1 Alberto 110 1007 2000-08-03
## 2 Alex 45 1009 1998-07-27
## 3 Allison 65 1005 1995-06-03
## 4 Ana 40 1013 1997-06-30
## 5 Arlene 50 1010 1999-06-11
## 6 Arthur 45 1010 1996-06-17
Para seleccionar las variables storm y pressure del data frame ejecutaremos la siguiente instrucción:
select(storms, storm, pressure)## Source: local data frame [6 x 2]
##
## storm pressure
## (chr) (int)
## 1 Alberto 1007
## 2 Alex 1009
## 3 Allison 1005
## 4 Ana 1013
## 5 Arlene 1010
## 6 Arthur 1010
Con el guión - podemos excluir una columna:

select(storms, -storm)## Source: local data frame [6 x 3]
##
## wind pressure date
## (int) (int) (date)
## 1 110 1007 2000-08-03
## 2 45 1009 1998-07-27
## 3 65 1005 1995-06-03
## 4 40 1013 1997-06-30
## 5 50 1010 1999-06-11
## 6 45 1010 1996-06-17
Podemos utilizar la notación : para seleccionar un rango de columnas:

select(storms, wind:date)## Source: local data frame [6 x 3]
##
## wind pressure date
## (int) (int) (date)
## 1 110 1007 2000-08-03
## 2 45 1009 1998-07-27
## 3 65 1005 1995-06-03
## 4 40 1013 1997-06-30
## 5 50 1010 1999-06-11
## 6 45 1010 1996-06-17
Utilizando los operadores - y : de forma conjunta podemos hacer cosas como estas:
select(storms, -(storm:wind))## Source: local data frame [6 x 2]
##
## pressure date
## (int) (date)
## 1 1007 2000-08-03
## 2 1009 1998-07-27
## 3 1005 1995-06-03
## 4 1013 1997-06-30
## 5 1010 1999-06-11
## 6 1010 1996-06-17
El paquete dplyr proporciona una serie de funciones que nos pueden facilitar mucho nuestro trabajo, como por ejemplo:
#Selecciona columnas cuyo nombre contiene un string
select(storms,starts_with("w"))## Source: local data frame [6 x 1]
##
## wind
## (int)
## 1 110
## 2 45
## 3 65
## 4 40
## 5 50
## 6 45
#Selecciona columnas cuyo nombre termina con un string
select(storms, ends_with("e"))## Source: local data frame [6 x 2]
##
## pressure date
## (int) (date)
## 1 1007 2000-08-03
## 2 1009 1998-07-27
## 3 1005 1995-06-03
## 4 1013 1997-06-30
## 5 1010 1999-06-11
## 6 1010 1996-06-17
#Selecciona todas las columnas
select(storms, everything())## Source: local data frame [6 x 4]
##
## storm wind pressure date
## (chr) (int) (int) (date)
## 1 Alberto 110 1007 2000-08-03
## 2 Alex 45 1009 1998-07-27
## 3 Allison 65 1005 1995-06-03
## 4 Ana 40 1013 1997-06-30
## 5 Arlene 50 1010 1999-06-11
## 6 Arthur 45 1010 1996-06-17
#Selecciona columnas cuyo nombres contienen un string
select(storms, contains("essure"))## Source: local data frame [6 x 1]
##
## pressure
## (int)
## 1 1007
## 2 1009
## 3 1005
## 4 1013
## 5 1010
## 6 1010
A continuación mostramos un resumen de las funciones para select que nos serán muy útiles:
| *A partir de la tercera fila son funciones propias del paquete dply | |
|---|---|
| - | Selecciona todas las variables excepto |
| : | Selecciona un rango |
| contains() | Selecciona variables cuyo nombre contiene la cadena de texto |
| ends_with() | Selecciona variables cuyo nombre termina con la cadena de caracteres |
| everything() | Selecciona todas las columnas |
| matches() | Selecciona las variables cuyos nombres coinciden con una expresión regular |
| num_range() | Selecciona las variables por posición |
| one_of() | Selecciona variables cuyos nombres están en un grupo de nombres |
| start_with() | Selecciona variables cuyos nombres empiezan con la cadena de caracteres |
filter()
La función filter nos permite filtrar filas según una condición:
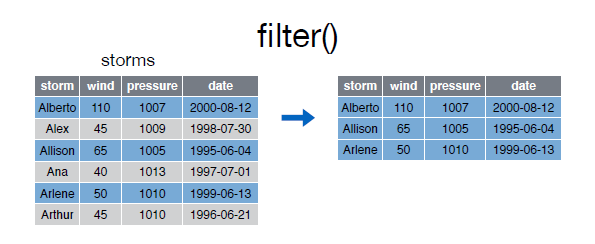
> filter(storms, wind >= 50)Source: local data frame [3 x 4]
storm wind pressure date
(chr) (int) (int) (date)
1 Alberto 110 1007 2000-08-03
2 Allison 65 1005 1995-06-03
3 Arlene 50 1010 1999-06-11
Se pueden incluir varias condiciones en un mismo filtro:
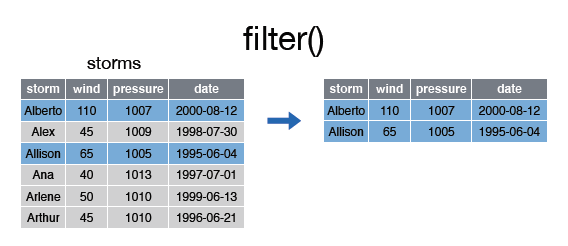
> filter(storms, wind >= 50, storm %in% c("Alberto", "Alex", "Allison"))Source: local data frame [2 x 4]
storm wind pressure date
(chr) (int) (int) (date)
1 Alberto 110 1007 2000-08-03
2 Allison 65 1005 1995-06-03
Las condiciones pueden ser expresiones logicas construidas mediante los operadores relacionales y lógicos:
| ?Comparison | |
|---|---|
| < | Menor que |
| > | Mayor que |
| == | Igual que |
| <= | Menor o igual que |
| >= | Mayor o igual que |
| != | Diferente que |
| %in% | Pertenece al conjunto |
| is.na | Es NA |
| !is.na | No es NA |
| ?base::Logic | |
|---|---|
| & | boolean and |
| | boolean o | |
| xor | or inclusivo |
| ! | not |
| any | cualquiera true |
| all | todos verdaderos |
Así por ejemplo, el siguiente ejemplo filtra aquellas filas con un wind >= 50 y pressure < 1010:
> filter(storms, wind>=50 & pressure<1010)Source: local data frame [2 x 4]
storm wind pressure date
(chr) (int) (int) (date)
1 Alberto 110 1007 2000-08-03
2 Allison 65 1005 1995-06-03
arrange()
La función arrange() se utiliza para ordenar las filas de un data frame de acuerdo a una o varias columnas/variables.
Por defecto arrange() ordena las filas por orden ascendente:
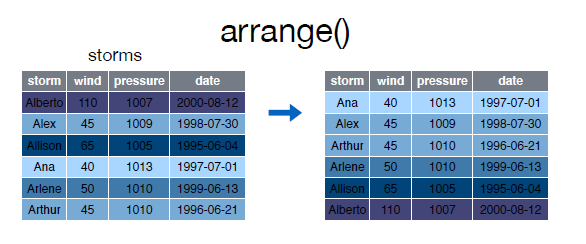
Echemos un vistazo al data frame arrange:
> stormsSource: local data frame [6 x 4]
storm wind pressure date
(chr) (int) (int) (date)
1 Alberto 110 1007 2000-08-03
2 Alex 45 1009 1998-07-27
3 Allison 65 1005 1995-06-03
4 Ana 40 1013 1997-06-30
5 Arlene 50 1010 1999-06-11
6 Arthur 45 1010 1996-06-17
Para ordenar las filas por la variable wind de forma ascendente podemos hacer lo siguiente:
> arrange(storms, wind)Source: local data frame [6 x 4]
storm wind pressure date
(chr) (int) (int) (date)
1 Ana 40 1013 1997-06-30
2 Alex 45 1009 1998-07-27
3 Arthur 45 1010 1996-06-17
4 Arlene 50 1010 1999-06-11
5 Allison 65 1005 1995-06-03
6 Alberto 110 1007 2000-08-03
Si las queremos ordenar de forma ascendente lo haremos del siguiente modo:

> arrange(storms, desc(wind))Source: local data frame [6 x 4]
storm wind pressure date
(chr) (int) (int) (date)
1 Alberto 110 1007 2000-08-03
2 Allison 65 1005 1995-06-03
3 Arlene 50 1010 1999-06-11
4 Alex 45 1009 1998-07-27
5 Arthur 45 1010 1996-06-17
6 Ana 40 1013 1997-06-30
Podemos ordenar las filas según varias variables:
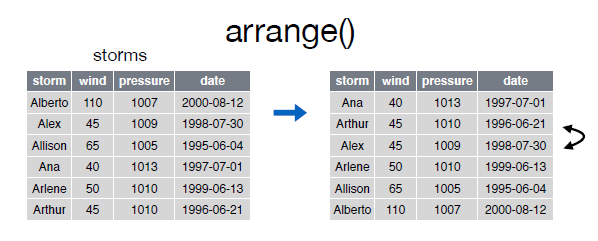
> stormsSource: local data frame [6 x 4]
storm wind pressure date
(chr) (int) (int) (date)
1 Alberto 110 1007 2000-08-03
2 Alex 45 1009 1998-07-27
3 Allison 65 1005 1995-06-03
4 Ana 40 1013 1997-06-30
5 Arlene 50 1010 1999-06-11
6 Arthur 45 1010 1996-06-17
> arrange(storms, wind, date)Source: local data frame [6 x 4]
storm wind pressure date
(chr) (int) (int) (date)
1 Ana 40 1013 1997-06-30
2 Arthur 45 1010 1996-06-17
3 Alex 45 1009 1998-07-27
4 Arlene 50 1010 1999-06-11
5 Allison 65 1005 1995-06-03
6 Alberto 110 1007 2000-08-03
rename()
Renombrar una variable en un data frame es sorprendentemente en R muy difícil de realizar. La función rename() esta diseñada para hacer este proceso de una forma más fácil.
Echemos un vistazo a los nombres de las variables en el data frame storms:
> names(storms)[1] "storm" "wind" "pressure" "date"
Para cambiar los nombres de las variables en el data frame storms a castellano, podriamos hacerlo de la forma siguiente:
> rename(storms, tormenta = storm, viento = wind, presion = pressure, fecha = date )Source: local data frame [6 x 4]
tormenta viento presion fecha
(chr) (int) (int) (date)
1 Alberto 110 1007 2000-08-03
2 Alex 45 1009 1998-07-27
3 Allison 65 1005 1995-06-03
4 Ana 40 1013 1997-06-30
5 Arlene 50 1010 1999-06-11
6 Arthur 45 1010 1996-06-17
mutate()
Con la función mutate() podemos computar tranformaciones de variables en un data frame. A menudo, tendremos la necesidad de crear nuevas variables que se calculan a partir de variables existentes,mutate() nos proporciona una interface clara para realizar este tipo de operaciones.
Así por ejemplo si deseamos calcular el ratio entre pressure y wind:
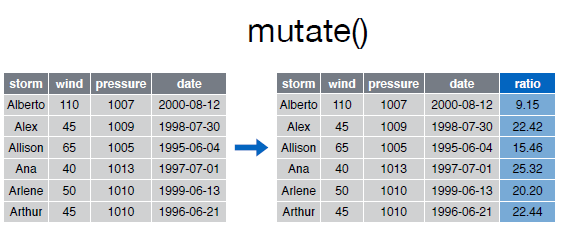
Echemos un vistazo al data frame storms:
> stormsSource: local data frame [6 x 4]
storm wind pressure date
(chr) (int) (int) (date)
1 Alberto 110 1007 2000-08-03
2 Alex 45 1009 1998-07-27
3 Allison 65 1005 1995-06-03
4 Ana 40 1013 1997-06-30
5 Arlene 50 1010 1999-06-11
6 Arthur 45 1010 1996-06-17
A continuación podemos crear una nueva varible ratio con el ratio entre la presión y el viento:
> mutate(storms, ratio = pressure/wind)Source: local data frame [6 x 5]
storm wind pressure date ratio
(chr) (int) (int) (date) (dbl)
1 Alberto 110 1007 2000-08-03 9.154545
2 Alex 45 1009 1998-07-27 22.422222
3 Allison 65 1005 1995-06-03 15.461538
4 Ana 40 1013 1997-06-30 25.325000
5 Arlene 50 1010 1999-06-11 20.200000
6 Arthur 45 1010 1996-06-17 22.444444
La función mutate() nos permite encadenar varias expresiones en una misma sentencia:
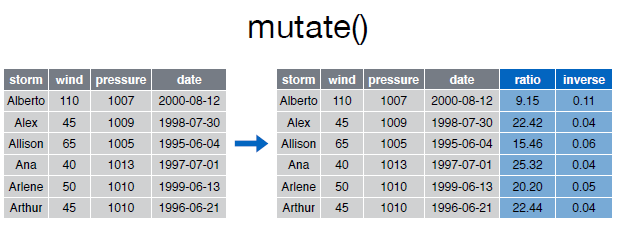
> mutate(storms, ratio=pressure/wind, inverse=ratio^-1)Source: local data frame [6 x 6]
storm wind pressure date ratio inverse
(chr) (int) (int) (date) (dbl) (dbl)
1 Alberto 110 1007 2000-08-03 9.154545 0.10923535
2 Alex 45 1009 1998-07-27 22.422222 0.04459861
3 Allison 65 1005 1995-06-03 15.461538 0.06467662
4 Ana 40 1013 1997-06-30 25.325000 0.03948667
5 Arlene 50 1010 1999-06-11 20.200000 0.04950495
6 Arthur 45 1010 1996-06-17 22.444444 0.04455446
Podemos utilizar funciones de otros paquetes como resultado de una nueva columna/variable, así por ejemplo si queremos calcular la distribución de frecuencias absolutas acumuladas de la variable wind podríamos utilizar la función cumsum() del paquete bas:
> mutate(storms, freq.acumulative = cumsum(wind))Source: local data frame [6 x 5]
storm wind pressure date freq.acumulative
(chr) (int) (int) (date) (int)
1 Alberto 110 1007 2000-08-03 110
2 Alex 45 1009 1998-07-27 155
3 Allison 65 1005 1995-06-03 220
4 Ana 40 1013 1997-06-30 260
5 Arlene 50 1010 1999-06-11 310
6 Arthur 45 1010 1996-06-17 355
Summarise
La función summarise() funciona de forma análoga a la función mutate, excepto que en lugar de añadir nuevas columnas crea un nuevo data frame.
Así por ejemplo, ara calcular la mediana y la varianza de la variable amount en el conjunto de datos pollution:

Echemos un vistazo al data frame pollution:
pollution## city size amount
## 1 New York large 23
## 2 New York small 14
## 3 London large 22
## 4 London small 16
## 5 Beijing large 121
## 6 Beijing small 56
Para obtener un resumen con la mediana y la varianza de la variable amount podemos hacer lo siguiente:
summarise(pollution, mediana = median(amount), variance = var(amount))## mediana variance
## 1 22.5 1731.6
Podemos utilizar el operador %>%,

pollution %>% summarise(mediana = median(amount), variance = var(amount))## mediana variance
## 1 22.5 1731.6
Obsérvese que las dos formas de hacerlo devuelven el mismo resultado.
A continuación se muestran funciones que trabajando conjuntamente con la función summarise() facilitarán nuestro trabajo diario. Las primeras pertenecen al paquete base y las otras son del paquete dplyr. Todas ellas toman como argumento un vector y devuelven un único resultado.
| base | |
|---|---|
| min(), max() | Valores max y min |
| mean() | media |
| median() | mediana |
| sum() | suma de los valores |
| var, sd() | varianza y desviación típica |
| dplyr | |
|---|---|
| first() | primer valor en un vector |
| last() | el último valor en un vector |
| n() | el número de valores en un vector |
| n_distinct() | el número de valores distintos en un vector |
| nth() | Extrar el valor que ocupa la posición n en un vector |
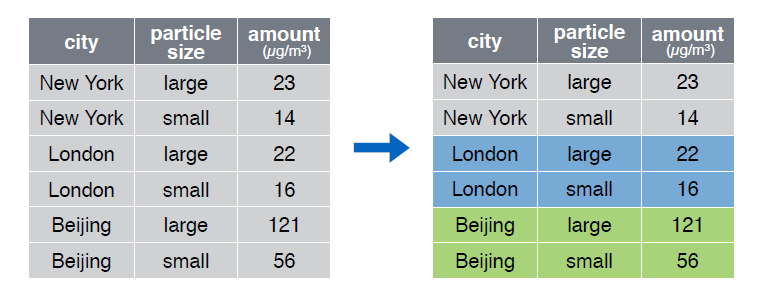
group_by()
La función group_by() agrupa un conjunto de filas seleccionado en un conjunto de filas de resumen de acuerdo con los valores de una o más columnas o expresiones.
Echemos un vistazo al data frame pollution:
> pollution city size amount
1 New York large 23
2 New York small 14
3 London large 22
4 London small 16
5 Beijing large 121
6 Beijing small 56
Agrupemos las observaciones por la variable city:
> group_by(pollution, city)Source: local data frame [6 x 3]
Groups: city [3]
city size amount
(chr) (chr) (dbl)
1 New York large 23
2 New York small 14
3 London large 22
4 London small 16
5 Beijing large 121
6 Beijing small 56
La función group_by() es extremadamente útil trabajando en conjunción con la función summarise():

> pollution %>% group_by(city) %>%
+ summarise(mean = mean(amount), sum = sum(amount), n = n())Source: local data frame [3 x 4]
city mean sum n
(chr) (dbl) (dbl) (int)
1 Beijing 88.5 177 2
2 London 19.0 38 2
3 New York 18.5 37 2
El operador pipe %>%
El operador pipeline %>% es útil para concatenar múltiples dplyr operaciones. Obsérvese en el siguiente ejemplo, que cada vez que queremos aplicar mas de una función, la instrucción es una secuencia de llamadas a funciones de forma anidada y que resulta ilegible:
third(second(first(x)))Este anidamiento no es una forma natural de expresar un secuencia de operaciones. El operador %>% nos permite escribir una secuencia de operaciones de izquierda a derecha:
first(x) %>% second(x) %>% third(x)Obsérvese que las siguientes instrucciones,


select(storms, storm, pressure)## Source: local data frame [6 x 2]
##
## storm pressure
## (chr) (int)
## 1 Alberto 1007
## 2 Alex 1009
## 3 Allison 1005
## 4 Ana 1013
## 5 Arlene 1010
## 6 Arthur 1010
filter(storms, wind >= 50)## Source: local data frame [3 x 4]
##
## storm wind pressure date
## (chr) (int) (int) (date)
## 1 Alberto 110 1007 2000-08-03
## 2 Allison 65 1005 1995-06-03
## 3 Arlene 50 1010 1999-06-11
es lo mismo que,
storms %>% select(storm, pressure)## Source: local data frame [6 x 2]
##
## storm pressure
## (chr) (int)
## 1 Alberto 1007
## 2 Alex 1009
## 3 Allison 1005
## 4 Ana 1013
## 5 Arlene 1010
## 6 Arthur 1010
storms %>% filter(wind >= 50)## Source: local data frame [3 x 4]
##
## storm wind pressure date
## (chr) (int) (int) (date)
## 1 Alberto 110 1007 2000-08-03
## 2 Allison 65 1005 1995-06-03
## 3 Arlene 50 1010 1999-06-11
Es en el siguiente ejemplo donde podemos observar el verdadero potencial del operador pipeline:
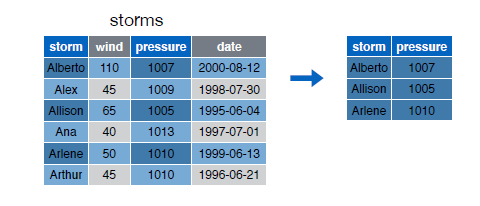
storms %>%
filter(wind>=50) %>%
select(storm, pressure)## Source: local data frame [3 x 2]
##
## storm pressure
## (chr) (int)
## 1 Alberto 1007
## 2 Allison 1005
## 3 Arlene 1010
El atajo de teclado para el operador %>% es